Note
Go to the end to download the full example code or to run this example in your browser via JupyterLite or Binder
Displaying Pipelines#
The default configuration for displaying a pipeline in a Jupyter Notebook is
'diagram' where set_config(display='diagram'). To deactivate HTML representation,
use set_config(display='text').
To see more detailed steps in the visualization of the pipeline, click on the steps in the pipeline.
Displaying a Pipeline with a Preprocessing Step and Classifier#
This section constructs a
Pipelinewith a preprocessing step,StandardScaler, and classifier,LogisticRegression, and displays its visual representation.
from sklearn import set_config
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
steps = [
("preprocessing", StandardScaler()),
("classifier", LogisticRegression()),
]
pipe = Pipeline(steps)
To visualize the diagram, the default is display='diagram'.
set_config(display="diagram")
pipe # click on the diagram below to see the details of each step
To view the text pipeline, change to display='text'.
set_config(display="text")
pipe
Pipeline(steps=[('preprocessing', StandardScaler()),
('classifier', LogisticRegression())])
Put back the default display
set_config(display="diagram")
Displaying a Pipeline Chaining Multiple Preprocessing Steps & Classifier#
This section constructs a
Pipelinewith multiple preprocessing steps,PolynomialFeaturesandStandardScaler, and a classifier step,LogisticRegression, and displays its visual representation.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
steps = [
("standard_scaler", StandardScaler()),
("polynomial", PolynomialFeatures(degree=3)),
("classifier", LogisticRegression(C=2.0)),
]
pipe = Pipeline(steps)
pipe # click on the diagram below to see the details of each step
Displaying a Pipeline and Dimensionality Reduction and Classifier#
Displaying a Complex Pipeline Chaining a Column Transformer#
This section constructs a complex
Pipelinewith aColumnTransformerand a classifier,LogisticRegression, and displays its visual representation.
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
numeric_preprocessor = Pipeline(
steps=[
("imputation_mean", SimpleImputer(missing_values=np.nan, strategy="mean")),
("scaler", StandardScaler()),
]
)
categorical_preprocessor = Pipeline(
steps=[
(
"imputation_constant",
SimpleImputer(fill_value="missing", strategy="constant"),
),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
[
("categorical", categorical_preprocessor, ["state", "gender"]),
("numerical", numeric_preprocessor, ["age", "weight"]),
]
)
pipe = make_pipeline(preprocessor, LogisticRegression(max_iter=500))
pipe # click on the diagram below to see the details of each step
Displaying a Grid Search over a Pipeline with a Classifier#
This section constructs a
GridSearchCVover aPipelinewithRandomForestClassifierand displays its visual representation.
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.model_selection import GridSearchCV
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
numeric_preprocessor = Pipeline(
steps=[
("imputation_mean", SimpleImputer(missing_values=np.nan, strategy="mean")),
("scaler", StandardScaler()),
]
)
categorical_preprocessor = Pipeline(
steps=[
(
"imputation_constant",
SimpleImputer(fill_value="missing", strategy="constant"),
),
("onehot", OneHotEncoder(handle_unknown="ignore")),
]
)
preprocessor = ColumnTransformer(
[
("categorical", categorical_preprocessor, ["state", "gender"]),
("numerical", numeric_preprocessor, ["age", "weight"]),
]
)
pipe = Pipeline(
steps=[("preprocessor", preprocessor), ("classifier", RandomForestClassifier())]
)
param_grid = {
"classifier__n_estimators": [200, 500],
"classifier__max_features": ["auto", "sqrt", "log2"],
"classifier__max_depth": [4, 5, 6, 7, 8],
"classifier__criterion": ["gini", "entropy"],
}
grid_search = GridSearchCV(pipe, param_grid=param_grid, n_jobs=1)
grid_search # click on the diagram below to see the details of each step
Total running time of the script: (0 minutes 0.101 seconds)
Related examples

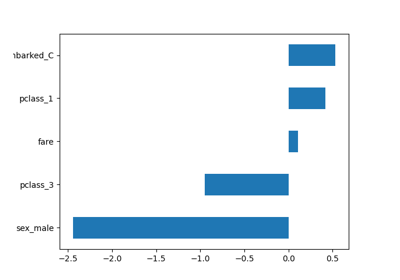
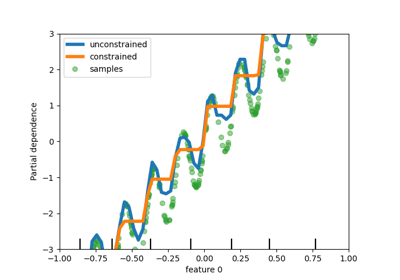
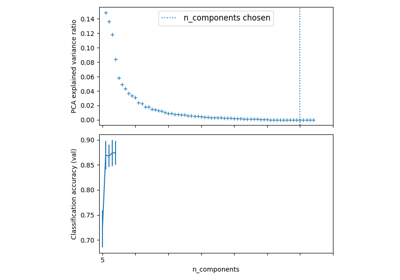
Pipelining: chaining a PCA and a logistic regression