sklearn.datasets.fetch_covtype#
- sklearn.datasets.fetch_covtype(*, data_home=None, download_if_missing=True, random_state=None, shuffle=False, return_X_y=False, as_frame=False)[source]#
Load the covertype dataset (classification).
Download it if necessary.
Classes
7
Samples total
581012
Dimensionality
54
Features
int
Read more in the User Guide.
- Parameters:
- data_homestr or path-like, default=None
Specify another download and cache folder for the datasets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
- download_if_missingbool, default=True
If False, raise an OSError if the data is not locally available instead of trying to download the data from the source site.
- random_stateint, RandomState instance or None, default=None
Determines random number generation for dataset shuffling. Pass an int for reproducible output across multiple function calls. See Glossary.
- shufflebool, default=False
Whether to shuffle dataset.
- return_X_ybool, default=False
If True, returns
(data.data, data.target)instead of a Bunch object.New in version 0.20.
- as_framebool, default=False
If True, the data is a pandas DataFrame including columns with appropriate dtypes (numeric). The target is a pandas DataFrame or Series depending on the number of target columns. If
return_X_yis True, then (data,target) will be pandas DataFrames or Series as described below.New in version 0.24.
- Returns:
- dataset
Bunch Dictionary-like object, with the following attributes.
- datandarray of shape (581012, 54)
Each row corresponds to the 54 features in the dataset.
- targetndarray of shape (581012,)
Each value corresponds to one of the 7 forest covertypes with values ranging between 1 to 7.
- framedataframe of shape (581012, 55)
Only present when
as_frame=True. Containsdataandtarget.- DESCRstr
Description of the forest covertype dataset.
- feature_nameslist
The names of the dataset columns.
- target_names: list
The names of the target columns.
- (data, target)tuple if
return_X_yis True A tuple of two ndarray. The first containing a 2D array of shape (n_samples, n_features) with each row representing one sample and each column representing the features. The second ndarray of shape (n_samples,) containing the target samples.
New in version 0.20.
- dataset
Examples
>>> from sklearn.datasets import fetch_covtype >>> cov_type = fetch_covtype() >>> cov_type.data.shape (581012, 54) >>> cov_type.target.shape (581012,) >>> # Let's check the 4 first feature names >>> cov_type.feature_names[:4] ['Elevation', 'Aspect', 'Slope', 'Horizontal_Distance_To_Hydrology']
Examples using sklearn.datasets.fetch_covtype#
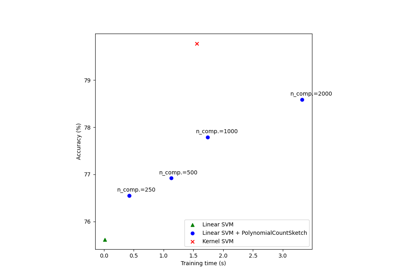
Scalable learning with polynomial kernel approximation