sklearn.datasets.fetch_openml#
- sklearn.datasets.fetch_openml(name: str | None = None, *, version: str | int = 'active', data_id: int | None = None, data_home: str | PathLike | None = None, target_column: str | List | None = 'default-target', cache: bool = True, return_X_y: bool = False, as_frame: str | bool = 'auto', n_retries: int = 3, delay: float = 1.0, parser: str = 'auto', read_csv_kwargs: Dict | None = None)[source]#
Fetch dataset from openml by name or dataset id.
Datasets are uniquely identified by either an integer ID or by a combination of name and version (i.e. there might be multiple versions of the ‘iris’ dataset). Please give either name or data_id (not both). In case a name is given, a version can also be provided.
Read more in the User Guide.
New in version 0.20.
Note
EXPERIMENTAL
The API is experimental (particularly the return value structure), and might have small backward-incompatible changes without notice or warning in future releases.
- Parameters:
- namestr, default=None
String identifier of the dataset. Note that OpenML can have multiple datasets with the same name.
- versionint or ‘active’, default=’active’
Version of the dataset. Can only be provided if also
nameis given. If ‘active’ the oldest version that’s still active is used. Since there may be more than one active version of a dataset, and those versions may fundamentally be different from one another, setting an exact version is highly recommended.- data_idint, default=None
OpenML ID of the dataset. The most specific way of retrieving a dataset. If data_id is not given, name (and potential version) are used to obtain a dataset.
- data_homestr or path-like, default=None
Specify another download and cache folder for the data sets. By default all scikit-learn data is stored in ‘~/scikit_learn_data’ subfolders.
- target_columnstr, list or None, default=’default-target’
Specify the column name in the data to use as target. If ‘default-target’, the standard target column a stored on the server is used. If
None, all columns are returned as data and the target isNone. If list (of strings), all columns with these names are returned as multi-target (Note: not all scikit-learn classifiers can handle all types of multi-output combinations).- cachebool, default=True
Whether to cache the downloaded datasets into
data_home.- return_X_ybool, default=False
If True, returns
(data, target)instead of a Bunch object. See below for more information about thedataandtargetobjects.- as_framebool or ‘auto’, default=’auto’
If True, the data is a pandas DataFrame including columns with appropriate dtypes (numeric, string or categorical). The target is a pandas DataFrame or Series depending on the number of target_columns. The Bunch will contain a
frameattribute with the target and the data. Ifreturn_X_yis True, then(data, target)will be pandas DataFrames or Series as describe above.If
as_frameis ‘auto’, the data and target will be converted to DataFrame or Series as ifas_frameis set to True, unless the dataset is stored in sparse format.If
as_frameis False, the data and target will be NumPy arrays and thedatawill only contain numerical values whenparser="liac-arff"where the categories are provided in the attributecategoriesof theBunchinstance. Whenparser="pandas", no ordinal encoding is made.Changed in version 0.24: The default value of
as_framechanged fromFalseto'auto'in 0.24.- n_retriesint, default=3
Number of retries when HTTP errors or network timeouts are encountered. Error with status code 412 won’t be retried as they represent OpenML generic errors.
- delayfloat, default=1.0
Number of seconds between retries.
- parser{“auto”, “pandas”, “liac-arff”}, default=”auto”
Parser used to load the ARFF file. Two parsers are implemented:
"pandas": this is the most efficient parser. However, it requires pandas to be installed and can only open dense datasets."liac-arff": this is a pure Python ARFF parser that is much less memory- and CPU-efficient. It deals with sparse ARFF datasets.
If
"auto", the parser is chosen automatically such that"liac-arff"is selected for sparse ARFF datasets, otherwise"pandas"is selected.New in version 1.2.
Changed in version 1.4: The default value of
parserchanges from"liac-arff"to"auto".- read_csv_kwargsdict, default=None
Keyword arguments passed to
pandas.read_csvwhen loading the data from a ARFF file and using the pandas parser. It can allow to overwrite some default parameters.New in version 1.3.
- Returns:
- data
Bunch Dictionary-like object, with the following attributes.
- datanp.array, scipy.sparse.csr_matrix of floats, or pandas DataFrame
The feature matrix. Categorical features are encoded as ordinals.
- targetnp.array, pandas Series or DataFrame
The regression target or classification labels, if applicable. Dtype is float if numeric, and object if categorical. If
as_frameis True,targetis a pandas object.- DESCRstr
The full description of the dataset.
- feature_nameslist
The names of the dataset columns.
- target_names: list
The names of the target columns.
New in version 0.22.
- categoriesdict or None
Maps each categorical feature name to a list of values, such that the value encoded as i is ith in the list. If
as_frameis True, this is None.- detailsdict
More metadata from OpenML.
- framepandas DataFrame
Only present when
as_frame=True. DataFrame withdataandtarget.
- (data, target)tuple if
return_X_yis True Note
EXPERIMENTAL
This interface is experimental and subsequent releases may change attributes without notice (although there should only be minor changes to
dataandtarget).Missing values in the ‘data’ are represented as NaN’s. Missing values in ‘target’ are represented as NaN’s (numerical target) or None (categorical target).
- data
Notes
The
"pandas"and"liac-arff"parsers can lead to different data types in the output. The notable differences are the following:The
"liac-arff"parser always encodes categorical features asstrobjects. To the contrary, the"pandas"parser instead infers the type while reading and numerical categories will be casted into integers whenever possible.The
"liac-arff"parser uses float64 to encode numerical features tagged as ‘REAL’ and ‘NUMERICAL’ in the metadata. The"pandas"parser instead infers if these numerical features corresponds to integers and uses panda’s Integer extension dtype.In particular, classification datasets with integer categories are typically loaded as such
(0, 1, ...)with the"pandas"parser while"liac-arff"will force the use of string encoded class labels such as"0","1"and so on.The
"pandas"parser will not strip single quotes - i.e.'- from string columns. For instance, a string'my string'will be kept as is while the"liac-arff"parser will strip the single quotes. For categorical columns, the single quotes are stripped from the values.
In addition, when
as_frame=Falseis used, the"liac-arff"parser returns ordinally encoded data where the categories are provided in the attributecategoriesof theBunchinstance. Instead,"pandas"returns a NumPy array were the categories are not encoded.Examples
>>> from sklearn.datasets import fetch_openml >>> adult = fetch_openml("adult", version=2) >>> adult.frame.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 48842 entries, 0 to 48841 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 48842 non-null int64 1 workclass 46043 non-null category 2 fnlwgt 48842 non-null int64 3 education 48842 non-null category 4 education-num 48842 non-null int64 5 marital-status 48842 non-null category 6 occupation 46033 non-null category 7 relationship 48842 non-null category 8 race 48842 non-null category 9 sex 48842 non-null category 10 capital-gain 48842 non-null int64 11 capital-loss 48842 non-null int64 12 hours-per-week 48842 non-null int64 13 native-country 47985 non-null category 14 class 48842 non-null category dtypes: category(9), int64(6) memory usage: 2.7 MB
Examples using sklearn.datasets.fetch_openml#


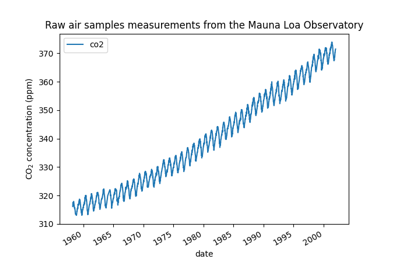
Forecasting of CO2 level on Mona Loa dataset using Gaussian process regression (GPR)
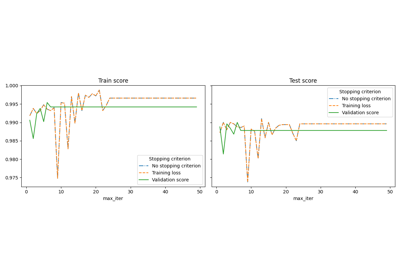

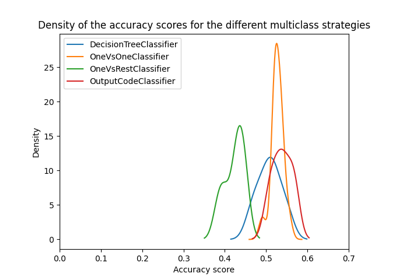
MNIST classification using multinomial logistic + L1
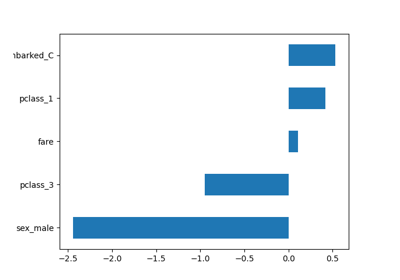
Common pitfalls in the interpretation of coefficients of linear models
Partial Dependence and Individual Conditional Expectation Plots
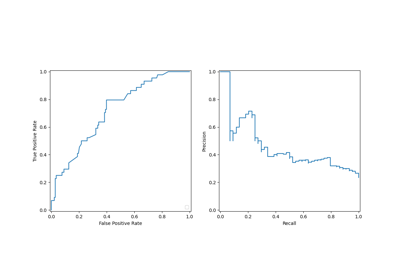
Permutation Importance vs Random Forest Feature Importance (MDI)
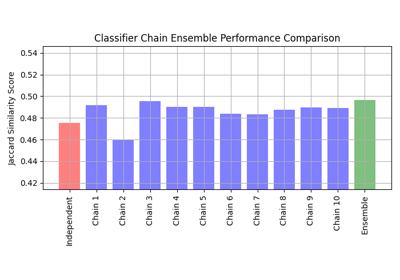
Multilabel classification using a classifier chain


Effect of transforming the targets in regression model