sklearn.datasets.make_hastie_10_2#
- sklearn.datasets.make_hastie_10_2(n_samples=12000, *, random_state=None)[source]#
Generate data for binary classification used in Hastie et al. 2009, Example 10.2.
The ten features are standard independent Gaussian and the target
yis defined by:y[i] = 1 if np.sum(X[i] ** 2) > 9.34 else -1
Read more in the User Guide.
- Parameters:
- n_samplesint, default=12000
The number of samples.
- random_stateint, RandomState instance or None, default=None
Determines random number generation for dataset creation. Pass an int for reproducible output across multiple function calls. See Glossary.
- Returns:
- Xndarray of shape (n_samples, 10)
The input samples.
- yndarray of shape (n_samples,)
The output values.
See also
make_gaussian_quantilesA generalization of this dataset approach.
References
[1]T. Hastie, R. Tibshirani and J. Friedman, “Elements of Statistical Learning Ed. 2”, Springer, 2009.
Examples using sklearn.datasets.make_hastie_10_2#
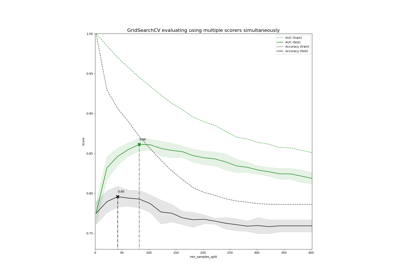
Demonstration of multi-metric evaluation on cross_val_score and GridSearchCV
Demonstration of multi-metric evaluation on cross_val_score and GridSearchCV